
spark大数据任务提交参数的优化记录分析
目录
起因
新接触一个spark集群,明明集群资源(core,内存)还有剩余,但是提交的任务却申请不到资源。
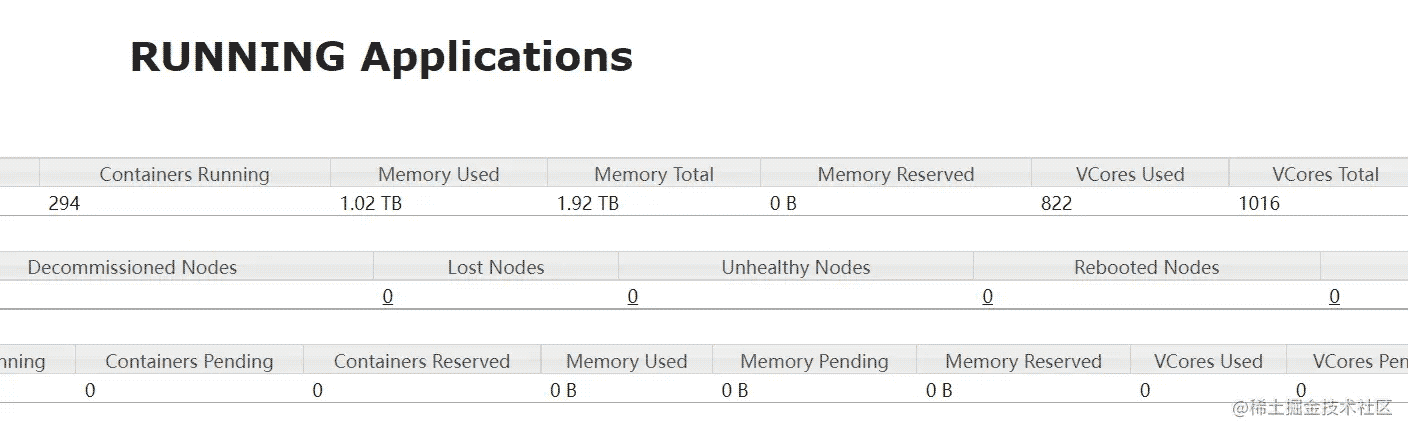
分析
环境
spark 2.2.0 基于yarn集群
参数
spark任务提交参数中最重要的几个:
spark-submit --master yarn --driver-cores 1 --driver-memory 5G --executor-cores 2 --num-executors 16 --executor-memory 4G
driver-cores driver端核数 driver-memory driver端内存大小 executor-cores 每个执行器的核数 num-executors 此任务申请的执行器总数 executor-memory 每个执行器的内存大小
那么,该任务将申请多少资源呢?
申请的执行器总内存数大小=num-executor * (executor-memory +spark.yarn.executor.memoryOverhead) = 16 * (4 + 2) = 96 申请的总内存=执行器总内存+dirver端内存=101 申请的总核数=num-executor*executor-core + yarn.AM(默认为1)=33 运行的总容器(contanier) = num-executor + yarn.AM(默认为1) = 17
所以这里还有一个关键的参数 spark.yarn.executor.memoryOverhead
这个参数是什么意思呢? 堆外内存,每个executor归spark 计算的内存为executor-memory,每个executor是一个单独的JVM,这个JAVA虚拟机本向在的内存大小即为spark.yarn.executor.memoryOverhead,不归spark本身管理。在spark集群中配置。
也可在代码中指定 spark.set("spark.yarn.executor.memoryOverhead", 1)
这部份实际上是存放spark代码本身的究竟,在executor-memory内存不足的时候也能应应急顶上。
问题所在
假设一个节点16G的内存,每个executor-memory=4,理想情况下4x4=16,那么该节点可以分配出4个节点供spark任务计算所用。 1.但应考虑到spark.yarn.executor.memoryOverhead. 如果spark.yarn.executor.memoryOverhead=2,那么每个executor所需申请的资源为4+2=6G,那么该节点只能分配2个节点,剩余16-6x2=4G的内存,无法使用。
如果一个集群共100个节点,用户将在yarn集群主界面看到,集群内存剩余400G,但一直无法申请到资源。
2.core也是一样的道理。
很多同学容易忽略spark.yarn.executor.memoryOverhead此参数,然后陷入怀疑,怎么申请的资源对不上,也容易陷入优化的误区。
优化结果
最终优化结果,将spark.yarn.executor.memoryOverhead调小,并根据node节点资源合理优化executor-memory,executor-core大小,将之前经常1.6T的内存占比,降到1.1左右。并能较快申请到资源。
以上就是spark任务提交参数的优化记录分析的详细内容,更多关于spark任务提交参数优化的资料请关注代码部落其它相关文章!
本文章来源于网络,作者是:是奉壹呀,由代码部落进行采编,如涉及侵权请联系删除!转载请注明出处:https://daimabuluo.cc/xiangguanjiqiao/1578.html
