
pytorch从头开始搭建UNet++的过程详解
目录
Unet是一个最近比较火的网络结构。它的理论已经有很多大佬在讨论了。本文主要从实际操作的层面,讲解pytorch从头开始搭建UNet++的过程。
Unet++代码
网络架构
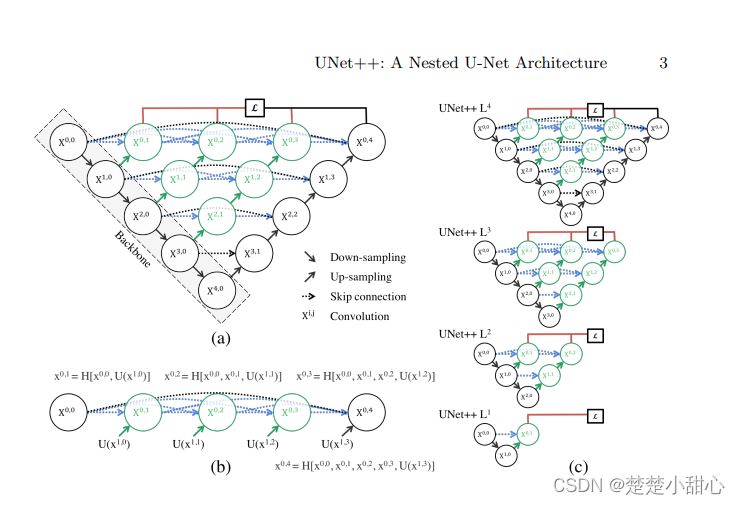
黑色部分是Backbone,是原先的UNet。
绿色箭头为上采样,蓝色箭头为密集跳跃连接。
绿色的模块为密集连接块,是经过左边两个部分拼接操作后组成的
Backbone
2个3x3的卷积,padding=1。
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
上采样
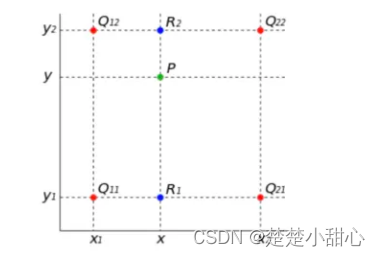
图中的绿色箭头,上采样使用双线性插值。
双线性插值就是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None)
参数说明:
①size:可以用来指定输出空间的大小,默认是None;
②scale_factor:比例因子,比如scale_factor=2意味着将输入图像上采样2倍,默认是None;
③mode:用来指定上采样算法,有’nearest’、 ‘linear’、‘bilinear’、‘bicubic’、‘trilinear’,默认是’nearest’。上采样算法在本文中会有详细理论进行讲解;
④align_corners:如果True,输入和输出张量的角像素对齐,从而保留这些像素的值,默认是False。此处True和False的区别本文中会有详细的理论讲解;
⑤recompute_scale_factor:如果recompute_scale_factor是True,则必须传入scale_factor并且scale_factor用于计算输出大小。计算出的输出大小将用于推断插值的新比例。请注意,当scale_factor为浮点数时,由于舍入和精度问题,它可能与重新计算的scale_factor不同。如果recompute_scale_factor是False,那么size或scale_factor将直接用于插值。
class Up(nn.Module):
def __init__(self):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return x
下采样
图中的黑色箭头,采用的是最大池化。
self.pool = nn.MaxPool2d(2, 2)
深度监督
所示,该结构下有4个分支,可以分为两种模式。
精确模式:4个分支取平均值结果
快速模式:只选择一个分支,其余被剪枝
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
网络架构代码
class NestedUNet(nn.Module):
def __init__(self, num_classes=1, input_channels=1, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = Up()
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(self.up(x1_0, x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(self.up(x2_0, x1_0))
x0_2 = self.conv0_2(self.up(x1_1, torch.cat([x0_0, x0_1], 1)))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(self.up(x3_0, x2_0))
x1_2 = self.conv1_2(self.up(x2_1, torch.cat([x1_0, x1_1], 1)))
x0_3 = self.conv0_3(self.up(x1_2, torch.cat([x0_0, x0_1, x0_2], 1)))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(self.up(x4_0, x3_0))
x2_2 = self.conv2_2(self.up(x3_1, torch.cat([x2_0, x2_1], 1)))
x1_3 = self.conv1_3(self.up(x2_2, torch.cat([x1_0, x1_1, x1_2], 1)))
x0_4 = self.conv0_4(self.up(x1_3, torch.cat([x0_0, x0_1, x0_2, x0_3], 1)))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
到此这篇关于pytorch从头开始搭建UNet++的过程详解的文章就介绍到这了,更多相关pytorch搭建UNet++内容请搜索代码部落以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码部落!
本文章来源于网络,作者是:楚楚小甜心,由代码部落进行采编,如涉及侵权请联系删除!转载请注明出处:https://daimabuluo.cc/xiangguanjiqiao/1650.html
