
Linux行处理工具之grep 正则表达式详解
目录
之前我们学习了
linux grep的基本操作,以及提及了linux grep的孪生兄弟egrep 和 fgrep,这次我们来看下。
在介绍正则表达式之前,我们先来尝试一下,假如有如下文本。
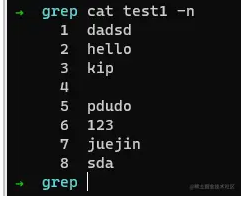
我们想获取空行,应该如何来写呢?
命令:
grep ^$ test1 -n
通过上述例子,我们使用正则表达式^$已经成功拿到了第四行数据,那么,这究竟如何解呢,我们细看博文。
正则表达式在grep应用以及差别
grep表达式有三种不同的版本,分别为basic(BRE) 、extended(ERE) 以及 perl(PCRE) ,我们grep默认支持的是BRE,而ERE是egrep支持的,或者说是grep -E支持的, 而PCRE则是grep -P支持的,那么这三者究竟有啥区别呢?
| BRE | ERE | PCRE | |||
|---|---|---|---|---|---|
| 任意字符 | . | . | . | ||
| 前一个字符0次或者出现1次 | ? | ? | ? | ||
| 前一个字符出现0次或无数次 | * | * | * | ||
| 前一个字符出现一个或者更多 | + | + | + | ||
| 字符集 | [...] | [...] | [...] | ||
| 字符集取反 | [^...] | [^...] | [^...] | ||
| 匹配前面字符出现的n次 | {n} | {n} | {n} | ||
| 匹配前面字符出现的n次以上 | {n,} | {n,} | {n,} | ||
| 匹配前面字符出现的n次到m次 | {n,m} | {n,m} | {n,m} | ||
| 开头 | |||||
| 结尾 | $ | $ | $ | ||
| 多表达式连接 | | | ||||
| 单词 | \w | \w | \w 或者 [[:word:]] | ||
| 字母大写/小写 | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | ||
| 非单词 | \W | ||||
| 空白字符 | \s 或者 [[:space:]] | \s 或者 [[:space:]] | |||
| 非空白字符 | [^[:space:]] | [^[:space:]] | \S | ||
| 数字 | \d 或者 [[:digit:]] | [[:digit:]] | [[:digit:]] | ||
| 非数字 | \D | [^[:digit:]] | [^[:digit:]] |
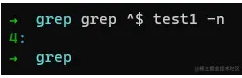
那么如何进行切换呢? 如上面所示,我们来看下。
如上所述,若我们需要连接多个匹配项,在BRE(grep)中则是|,而在ERE(egrep)和PCRE(grep -P)中则是|,所以我们可以顺利获取出结果,更多匹配项如上所述
匹配案例
匹配电话号码
若电话号码为xxx-xxxx-xxxx类型的,如何进行匹配呢? 我们可以使用'[0-9]{3}-[0-9]{4}-[0-9]{4}'进行匹配。
例如:
命令:
echo "telphone: 180-1234-5678" | grep '[0-9]{3}-[0-9]{4}-[0-9]{4}' -o

同样的,该方法还可以用来匹配其ip地址,正则: [0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}

匹配空行
若我们想匹配空行,则可以使用^$进行匹配,即: 开头就是结尾。
例如:
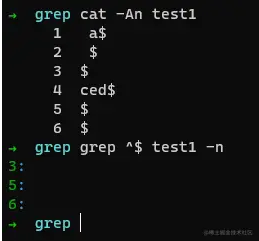
如上命令,我们顺利取出了 第3、5、6行数据
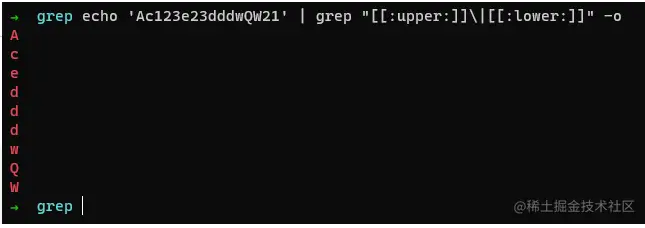
匹配所有字母
命令:
echo 'Ac123e23dddwQW21' | grep "[[:upper:]]|[[:lower:]]" -o
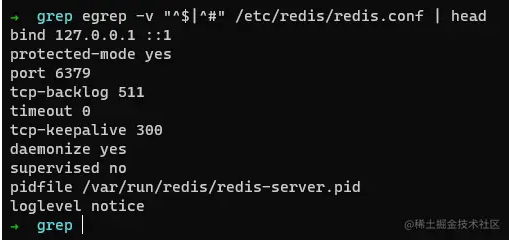
取出redis在使用的配置文件
我们知道redis服务器是以#来注释的,我们可以利用grep或者egrep来过滤掉注释和空格,例如:
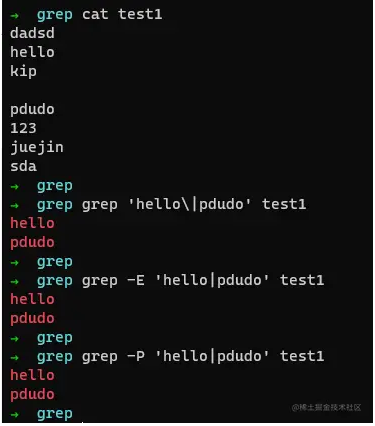
fgrep
fgrep最为简单,它不会启用正则表达式,而是按照字符来进行搜索,什么意思呢? 我们举个小案例就清楚了,
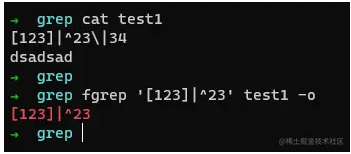
它不会进行任何正则匹配,所以可以直接使用搜索选就成,不用考虑转移啥的。
总结
我们一般将BRE称之为 基本正则表达式、ERE称之为 扩展正则表达式 而 PCRE称之为Perl兼容的正则表达式,如上正则表达式不是grep工具所实现的,而是单独的一套表达式,有很多语言在使用中,例如 sed默认正则表达式是 BRE, 而我们之前所学习的awk使用的正则表达式则是ERE,是不是感觉知识被串联起来了呢,好巧,我也是,怎么样,快来动手试验一下吧。
到此这篇关于Linux行处理工具之grep 正则表达式详解的文章就介绍到这了,更多相关linux grep 正则表达式内容请搜索代码部落以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码部落!
本文章来源于网络,作者是:pdudo,由代码部落进行采编,如涉及侵权请联系删除!转载请注明出处:https://daimabuluo.cc/zhengzebiaodashi/571.html
