
linux grep与正则表达式使用介绍
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。Unix的grep家族包括grep、egrep和fgrep。Windows系统下类似命令FINDSTR。
grep egrep fgrep(不支持正则表达式)
grep需要标准输入 因此常常位于管道右侧
命令参数:
--color=auto: 对匹配到的文本着色显示
-v: 显示不被pattern匹配到的行
-i: 忽略字符大小写
-n:显示匹配的行号
-c: 统计匹配的行数
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-A #: after, 后#行
-B #: before, 前#行
-C #:context, 前后各#行
-e:实现多个选项间的逻辑or关系
grep –e ‘cat ' -e ‘dog' file
-w:匹配整个单词 数字加字母下划线全都算单词的一部分,其他的都是单词的分隔符
-E:相当于egrep
-F:相当于fgrep,不支持正则表达式
-f: 跟一个文件(写有不同字符)进行内容检索是逻辑or关系
练习题:
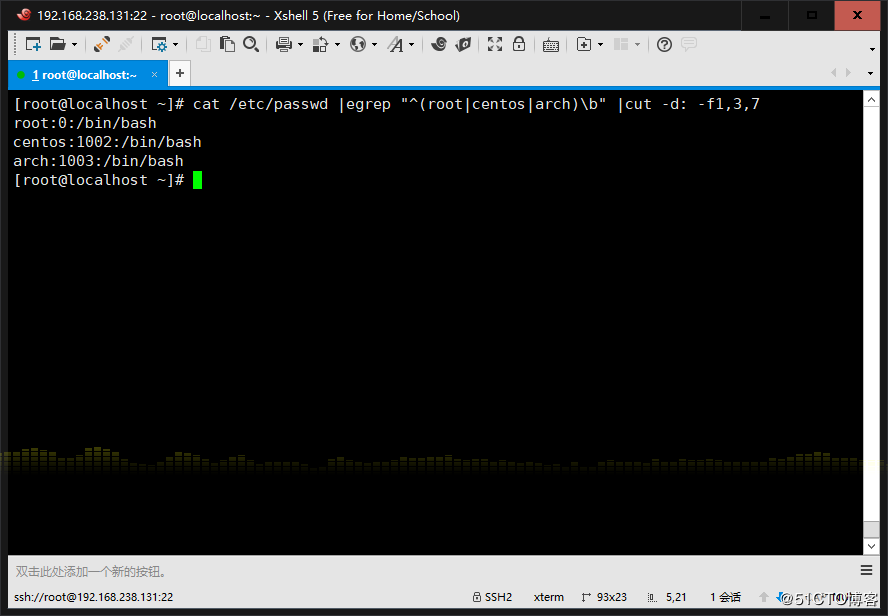
1、显示三个用户root、centos、arch的UID和默认shell (用户需要自己创建)
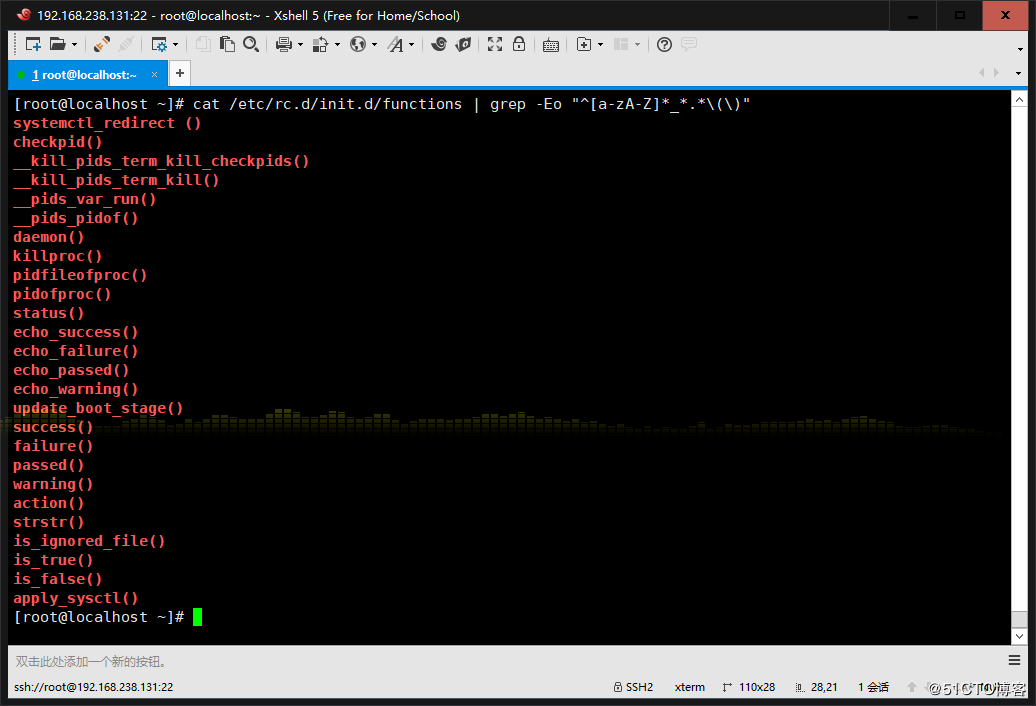
2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一 个小括号的行
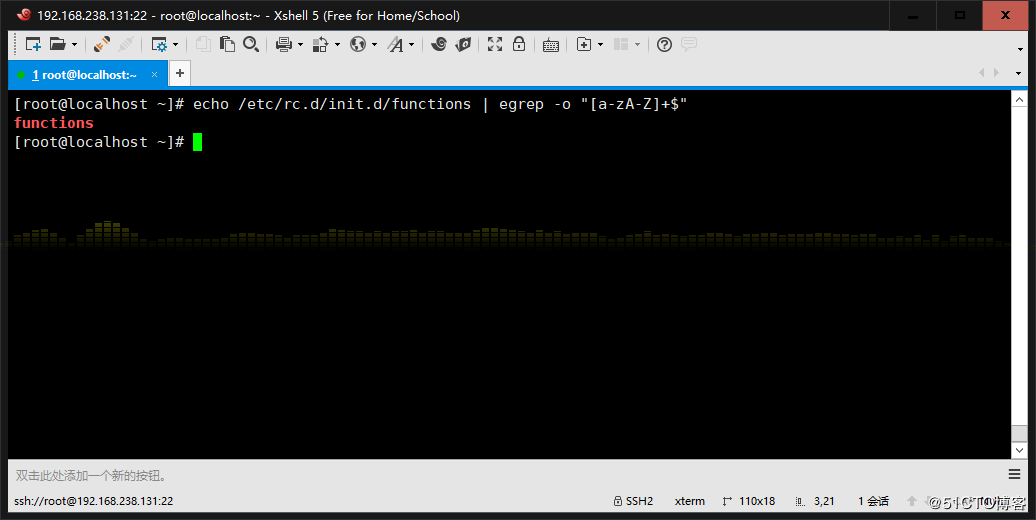
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
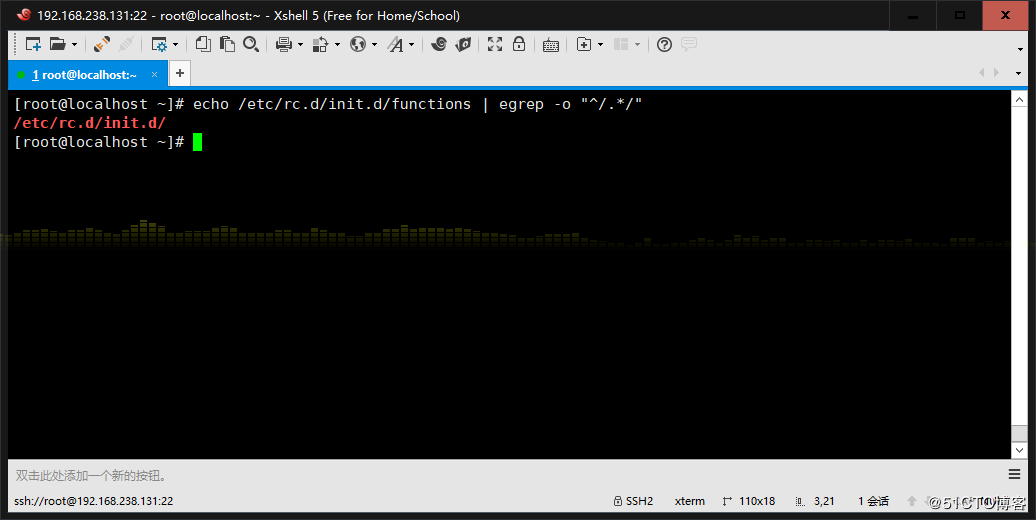
4、使用egrep取出上面路径的目录名
5、统计last命令中以root登录的每个主机IP地址登录次数
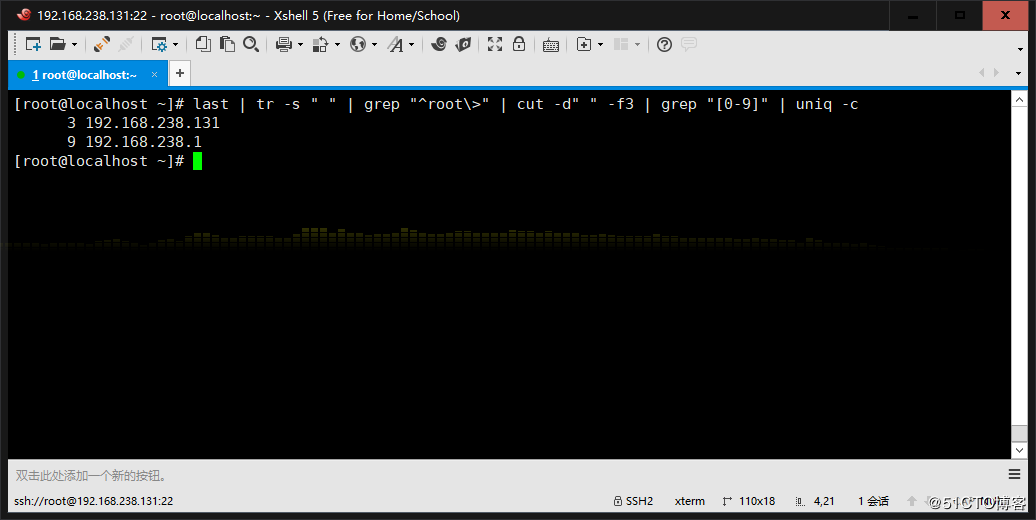
6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
0-9: [0-9]
10-99: [1-9][0-9]
100-199: 1[0-9][0-9]
200-249: 2[0-5][0-9]
250-255: 25[0-5]
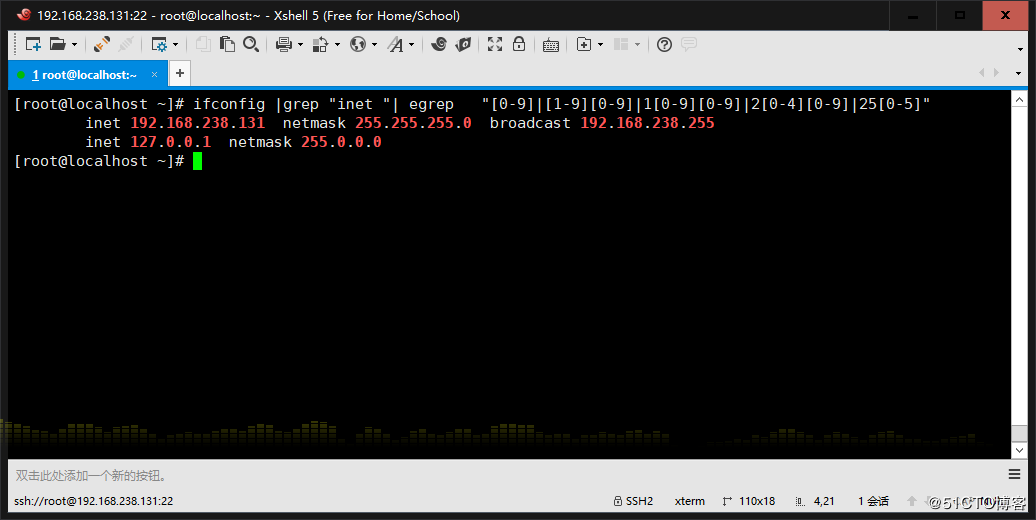
7、显示ifconfig命令结果中所有IPv4地址
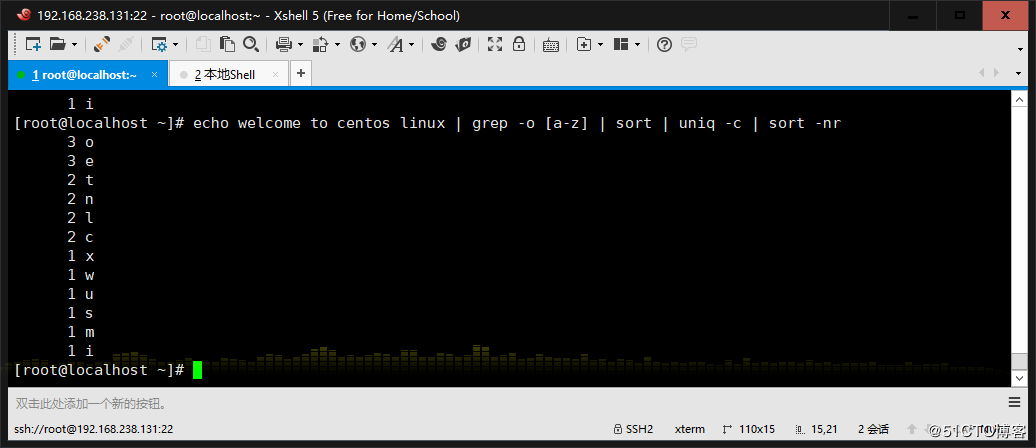
8、将此字符串:welcome to centos linux 中的每个字符排序,重复 次数多的排到前面
正则表达式:
REGEXP:由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符) 不表示字符字面意义,而表示控制或通配的功能
程序支持:grep,sed,awk,vim, less,nginx,varnish等
分两类:
基本正则表达式:BRE
扩展正则表达式:ERE
grep -E, egrep
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块
PCRE(Perl Compatible Regular Expressions)
元字符分类:字符匹配、匹配次数、位置锚定、分组
man 7 regex
字符匹配:
. 匹配任意单个字符 默认是贪婪匹配
[] 匹配指定范围内的任意单个字符 .在里面也是点不需要转义
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次
贪婪模式:尽可能的匹配符合条件的字符
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n
位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定;用于单词模式的右侧
\<PATTERN\> 匹配整个单词
分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如: \(root\)\+
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,
这些变量的命名方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例: \(string1\+\(string2\)*\)
\1 :string1\+\(string2\)*
\2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
扩展的正则表达式:
egrep = grep -E
egrep [OPTIONS] PATTERN [FILE...]
扩展正则表达式的元字符:
字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
次数匹配:
*:匹配前面字符任意次
?: 0或1次
+:1次或多次
{m}:匹配m次
{m,n}:至少m,至多n次
位置锚定:
^ :行首
$ :行尾
\<, \b :语首
\>, \b :语尾
分组:
() 后向引用:\1, \2, ...
或者:
a|b: a或b C|cat: C或cat (C|c)at:Cat或cat
练习题:
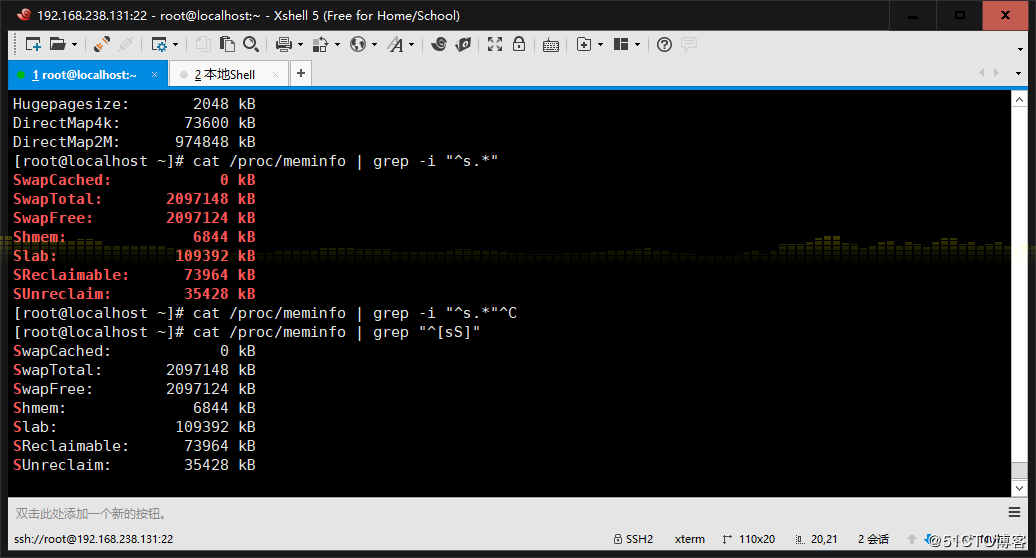
1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
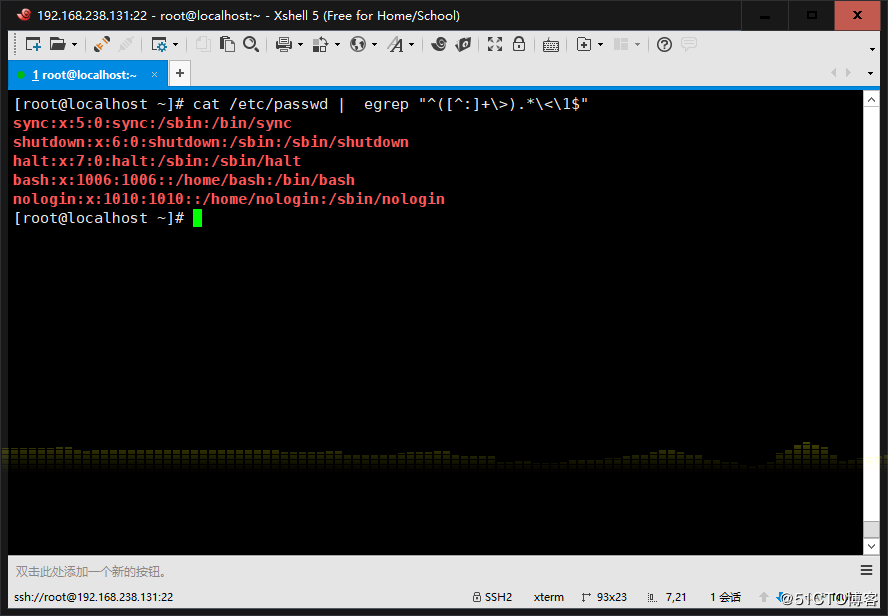
2、显示/etc/passwd文件中不以/bin/bash结尾的行
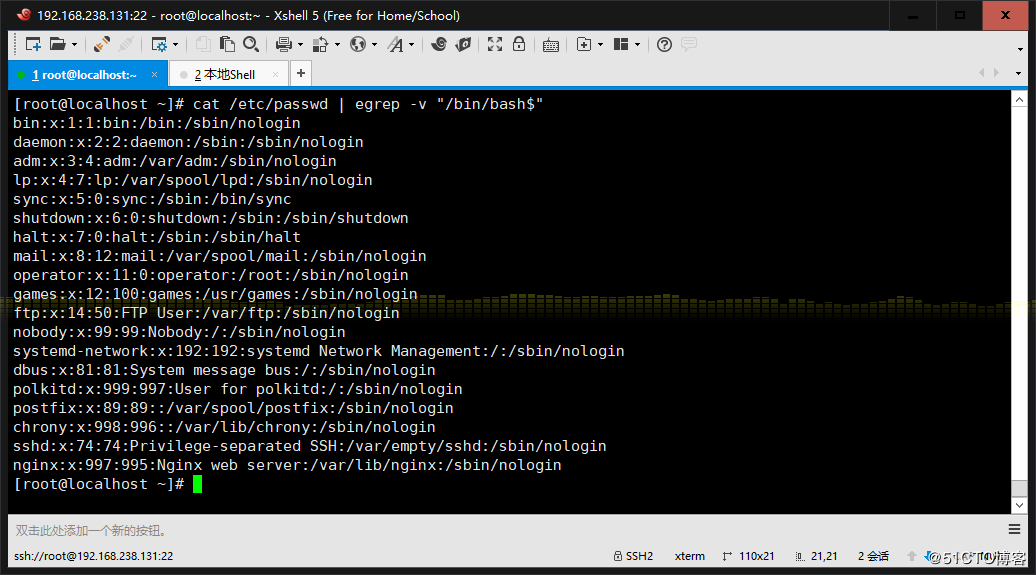
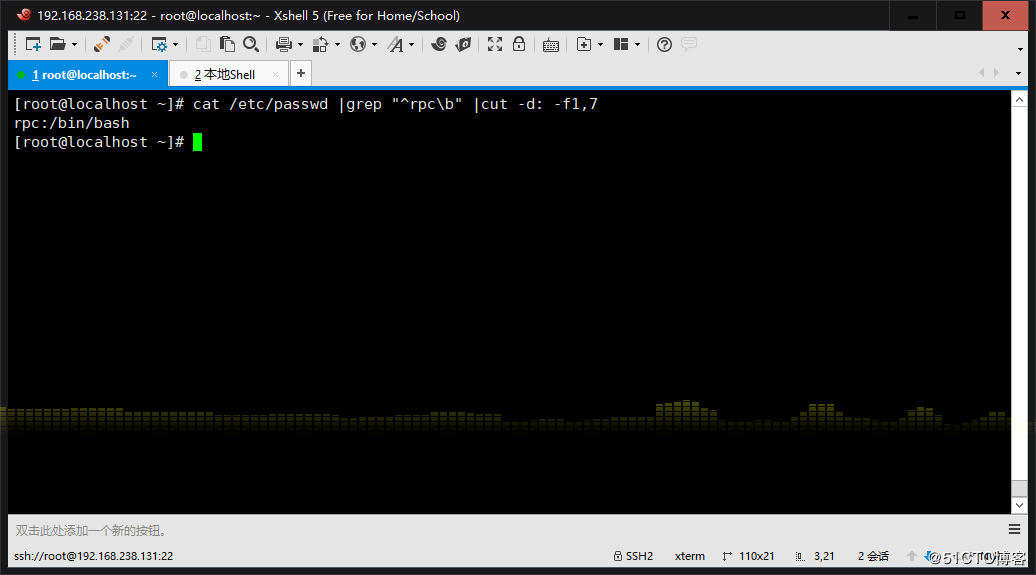
3、显示用户rpc默认的shell程序
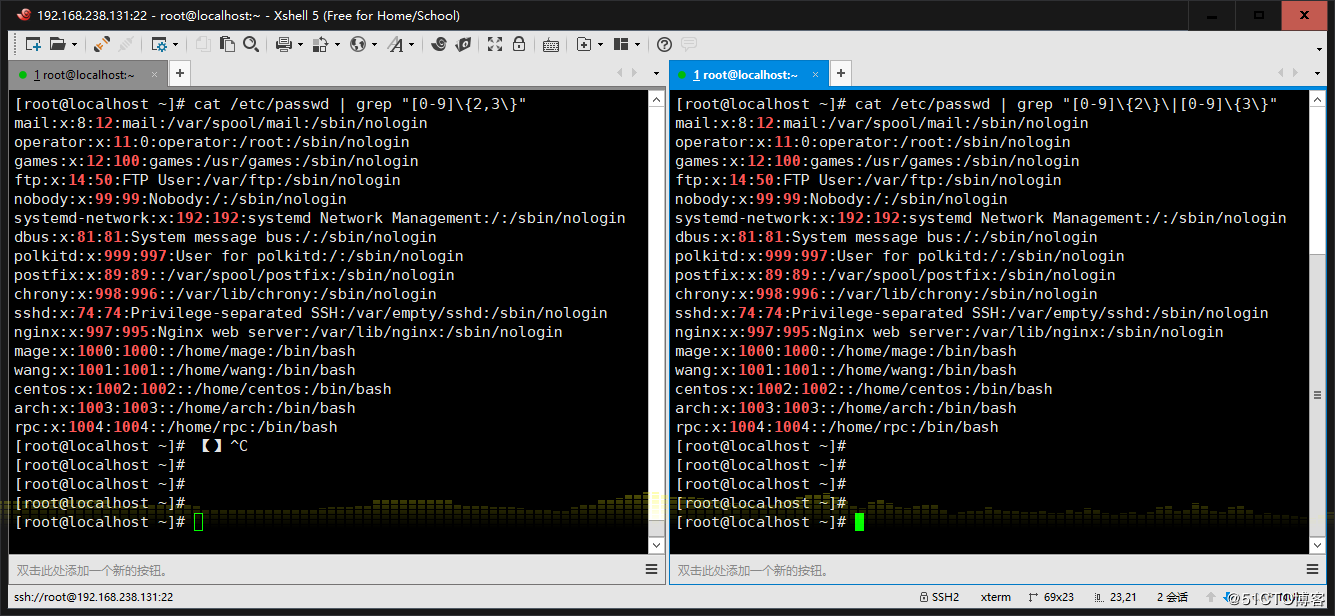
4、找出/etc/passwd中的两位或三位数 (只要数字的话可以加-o选项仅仅显示数字)
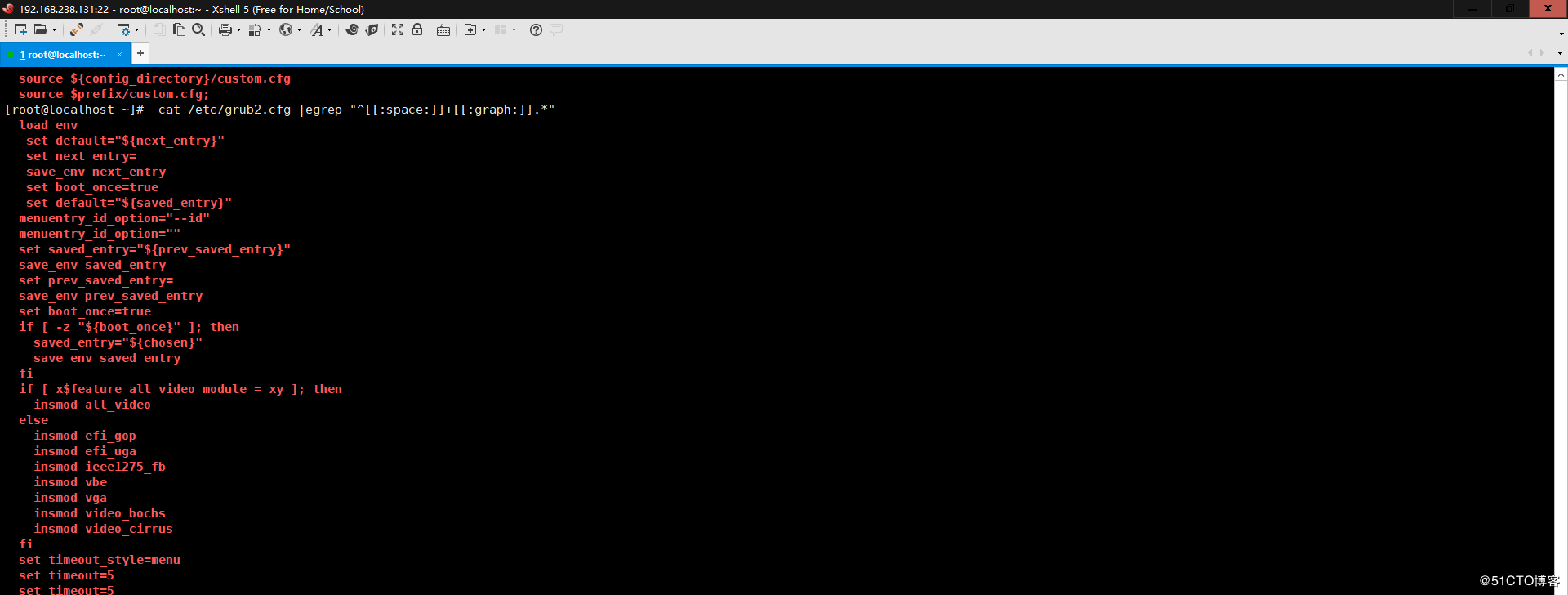
5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非 空白字符的行
6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
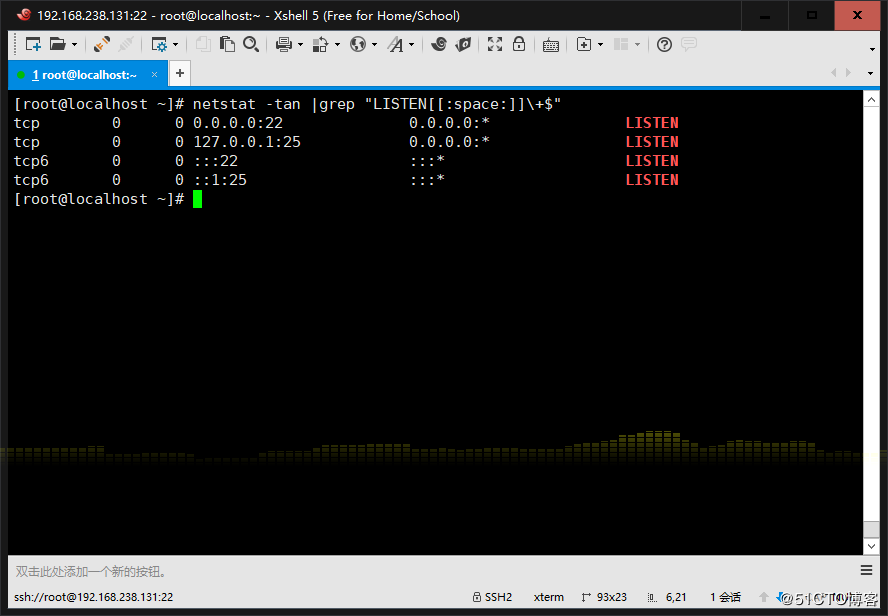
7、显示CentOS7上所有系统用户的用户名和UID
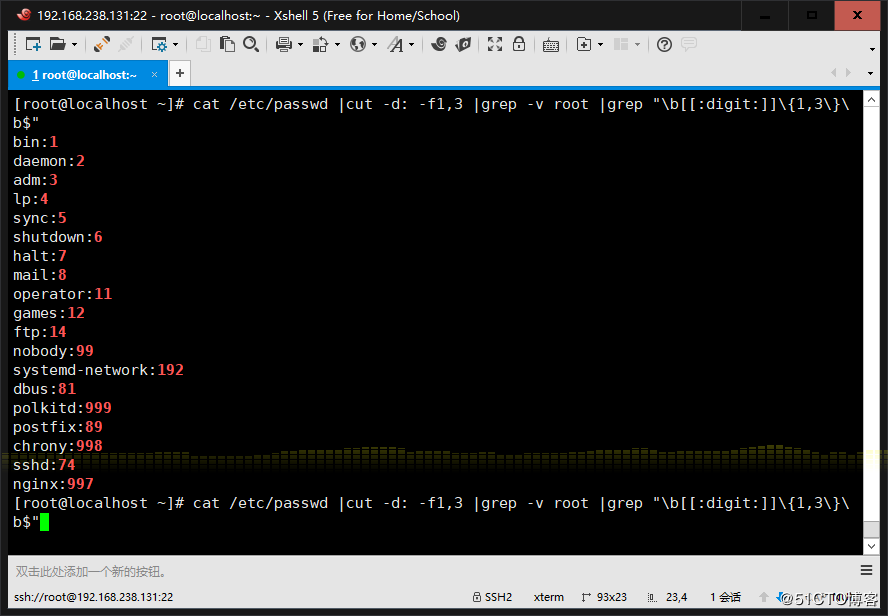
8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找 出/etc/passwd用户名和shell同名的行
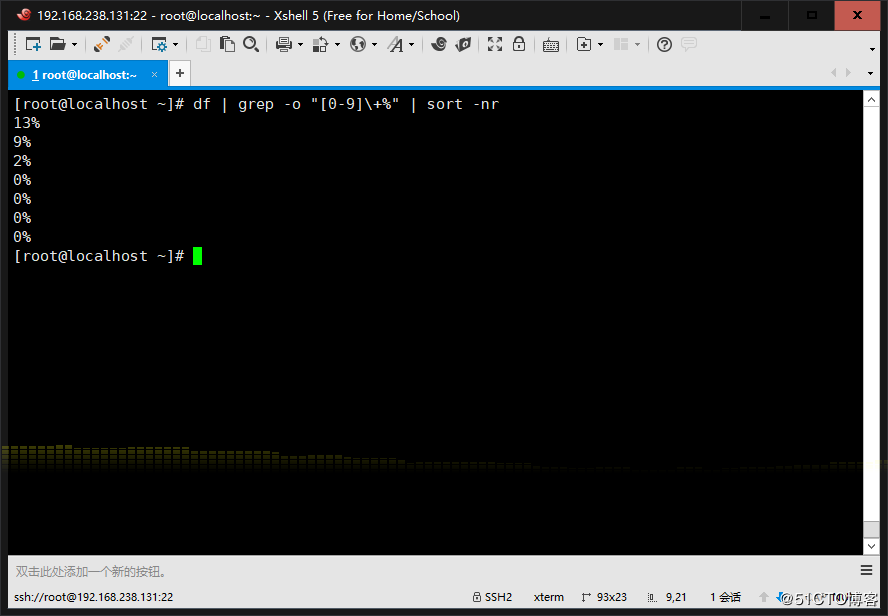
9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
grep和正则表达式参数
一:grep参数
1,-n :显示行号

2,-o :只显示匹配的内容

3,-q :静默模式,没有任何输出,得用$?来判断执行成功没有,即有没有过滤到想要的内容
4,-l :如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用,grep -rl 'root' /etc
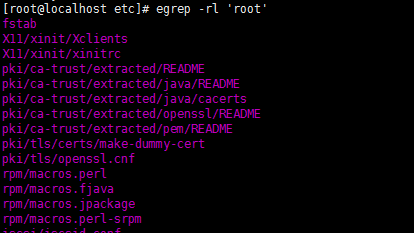 ,
,
5,-A :如果匹配成功,则将匹配行及其后n行一起打印出来

6,-B :如果匹配成功,则将匹配行及其前n行一起打印出来
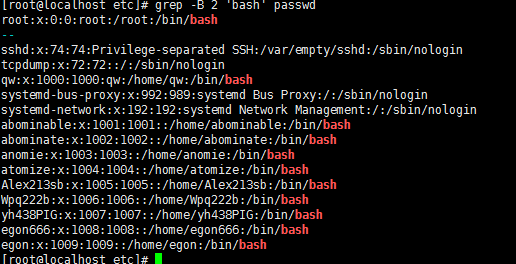
7,-C :如果匹配成功,则将匹配行及其前后n行一起打印出来
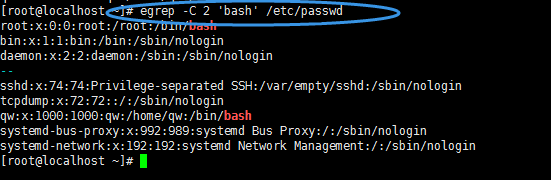
8,-c :如果匹配成功,则将匹配到的行数打印出来

9,-E :等于egrep,扩展
10,-i :忽略大小写
11,-v :取反,不匹配
12,-w:匹配单词
二:正则介绍
首先建a.txt。在进行验证
1,^ 行首
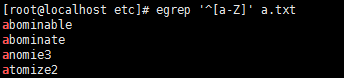
2,$行尾

3,.除了换行符以外的任意单个字符
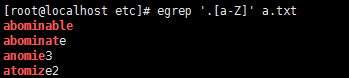
4,*前导字符的零个或多个

5, .*所有字
6, []字符组内的任一字符

7,[^]对字符组内的每个字符取反(不匹配字符组内的每个字符)

8, ^[^]非字符组内的字符开头的行

9,[a-z] 小写字母
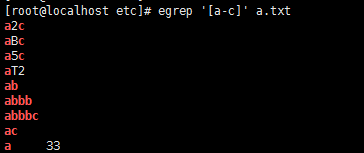
10,[A-Z] 大写字母

11,[a-Z] 小写和大写字母
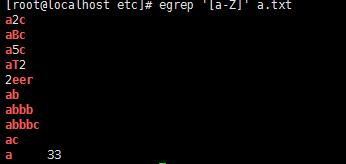
12,[0-9] 数字
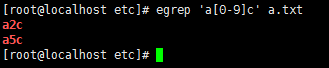
13,\<单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\>单词尾


以上就是linux grep与正则表达式使用介绍的详细内容,更多关于grep和正则表达式参数的资料请关注代码部落其它相关文章!
本文章来源于网络,作者是:Doumadouble,由代码部落进行采编,如涉及侵权请联系删除!转载请注明出处:https://daimabuluo.cc/zhengzebiaodashi/651.html
